Jekyll2024-02-22T12:49:29+00:00/feed.xmlAll NaNs!A smorgasbord of science and softwareUncertaintext for uncertain numbers2023-09-02T04:00:00+00:002023-09-02T04:00:00+00:00/2023/09/02/uncertaintext
import uncertaintext from "/assets/2023-09-02-uncertaintext/uncertaintext.js";
uncertaintext();
In scientific writing, the typical ways to report uncertainty are with the
friendly plus-or-minus sign, e.g., 1.5 ± 0.05, or the more concise parenthesis
notation, e.g., 1.5(5).
These representations are understood to give a range within which the true
value is likely to fall – the textual equivalent of error bars in a plot.
While it can be tricky to pin down the precise meaning of the stated
uncertainty (a 95% confidence interval? the standard error? a Bayesian credible
interval?), authors can spill a little extra ink to indicate what kind of range
they have shown and the notation works just fine.
In popular writing, it seems more common to avoid any technical notation (e.g.,
±). Instead, you are likely to see either a range of values (e.g. “between 1 and 3”)
or just some fuzzy modifier (e.g., “about 2”). This approach trades detail
about the uncertainty for approachability, which makes perfect sense for a
more informal target audience.
Where I think both approaches come up short is in conveying an intuition of
what values are likely. Sure, the information is there, but we know that
probability is hard and uncertainty often misunderstood.
My uncertaintext project is a little experiment aimed at
delivering this intuition. Let’s take advantage of the fact the webpages need
not be static, and see what happens if we display uncertain values as a simple
text-only animation of samples from some underlying distribution.
Uncertaintext in action
Take this example sentence about the current estimate of sea level rise
provided by NASA:
Satellite sea level observations show 101 ± 4.0 mm rise in global sea level since 1993.
Let’s jazz it up a bit using the uncertaintext library.
Taking a guess that the measurement uncertainty is Gaussian, and that the
stated 4.0 mm range is two standard deviations, we can tell uncertaintext to
display samples from a normal distributes with mean 101 and standard deviation
2.0 mm. Observe the fun!
Satellite sea level observations show
mm
rise in global sea level since 1993.
Maybe that’s too much precision? We can update the format to give fewer digits.
Satellite sea level observations show
mm
rise in global sea level since 1993.
Maybe that update cadence is too fast and giving you a headache? We can specify
the update in “frames-per-second” to slow things down. The previous example updates
5 times per second, so let’s reduce that to 2.
Satellite sea level observations show
mm
rise in global sea level since 1993.
Maybe you want a different distribution? We can try a uniform distribution
instead, here with a minimum of 97 and a maxium of 105.
Satellite sea level observations show
mm
rise in global sea level since 1993.
Personally, I find this dynamic representation informative, if a bit silly. I
think that it does impart a more visceral feel for the certainty of the
estimated value.
As a final example, say we have two estimates with the same expected value but
different standard deviations. Displaying these with uncertaintext hammers home
the difference in a quite satisfying way:
Standard Notation
1 ± 0.01
1 ± 0.5
Uncertaintext
How to use it
Uncertaintext is a javascript module which finds HTML elements with
class=uncertaintext, parses special dataset attributes that define the
distribution, format, and update interval, and then inserts random samples into
the element’s innerHTML.
First, download uncertaintext.js and put it somewhere
accessable to your webpage.
Then, import the main uncertaintext function into your page and run it, like so:
I’ve found that using a monospace font is essential too. Otherwise, the
changing character widths nudge the surrounding text and make the page layout
unstable. A little bit of styling does the trick:
Lastly, add <span> elements where you want uncertaintext to display random
samples from a given distribution. For example:
<span class=uncertaintext data-uct-distrib=normal data-uct-mu=1 data-uct-sigma="0.01"></span>
This is, in fact, exactly how this blog post uses uncertaintext. For more
details on available distributions and other formatting options, take a look at
the README for the project.
]]>Always Insult Me: an insult-error update2020-04-18T11:00:00+00:002020-04-18T11:00:00+00:00/jekyll/update/2020/04/18/always-insult-meYou may recall the amazing insult-error python package
from a “recent” post. Well, great news! It is now slightly
better in version 0.3.1.
This update brings a new feature to make it super easy to start insulting friends and enemies alike.
Running the always_insult_me function will rejigger your environment to convert all uncaught exceptions
into InsultErrors with the usual random insults and (optionally) messages. If you get sick of this
behavior, dont_always_insult_me will set things back to normal.
A little example to demonstrate:
frominsult_errorimportalways_insult_me,dont_always_insult_me# turn on ubiquitous insults
# uncaught exceptions converted to InsultErrors and messages replaced too
always_insult_me()raiseValueError('a normal message')# >>>
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# FuckYouBuddy: I don't have the time or the crayons to explain this to you
# turn off insults, things go back to normal
dont_always_insult_me()raiseValueError('another normal message')# >>>
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# ValueError: another normal message
# turn insults back on, but this time preserve error messages
always_insult_me(preserve_msg=True)raiseValueError('a normal message')# >>>
# Traceback (most recent call last):
# File "<stdin>", line 1, in <module>
# FuckYouBuddy: a normal message
Credit to Jacob McDonald (my colleague at Indigo Ag) for the idea and initial implementation. This feature
works by modifying the sys.excepthook callable, which is executed just before Python fails due to an
uncaught exception. Happily, the original value of this callable is preserved as sys.__excepthook__, so
we can easily undo the change.We simply wrap the original hook such that the exception type becomes an InsultError,
but the traceback is unchanged. This is important because we want to insult people, but not fuck up
their workflow.
Some internals have changed as well since the last post. Most notably, error names are handled in
a much simpler way. Rather than mucking about with __new__ and exception subclasses, we just
modify the exception ___class__.__name__ attribute during exception initialization. We still
have an InsultError instance, but it has a nice random name. Python really let’s you do any
damn thing you want.
Lastly, there are a few new insults in there since my last post. Still looking for contributions, of course!
]]>newmatic: MAT-files optimized for partial reading and writing of large arrays2020-02-23T03:45:00+00:002020-02-23T03:45:00+00:00/jekyll/update/2020/02/23/newmatic
This post describes a tool I wrote to solve an annoying problem I ran into in
my PhD research when processing (relatively) large stacks of images in MATLAB.
To get the newmatic package or see an example, check out:
newmatic provides a bit of extra control over data formatting, and
the results are pretty nice. The example included in the
package provides a whiff of the potential performance benefits. The table below
compares timings for complete (i.e., whole variable) and partial IO for the
native matfile and my newmatic functions.
write-time-seconds
read-time-seconds
file-size-MB
native-complete
4.83
1.18
95.53
newmatic-complete
4.84
1.19
95.53
native-partial
87.72
5.93
116.33
newmatic-partial
4.87
0.24
95.82
Using newmatic makes partial access roughly the same speed as reading/writing whole
variables, and does not have a significant impact on file size. For this specific example,
setting a sane chunk size yields ~20x speedup.
A Chunky Problem
I had a directory full of images to analyze, and wanted to save the results to
a single file with nicely defined coordinates. Given the size of the dataset,
partial reading/writing was essential as well. NetCDF is a natural fit for this
task, but my collegues found that to be an unfriendly format, and strongly
prefered MAT-files.
This seemed fine, since MAT-files are HDF5 formatted under the hood, and MATLAB
support partial reading/writing. Unfortunately, performance was truly terrible,
and processing ground to a halt waiting for IO.
Peaking at the MAT-files with h5dump -H -p, it was clear that the problem was
MATLAB had chosen a pathologically bad chunk size for my use case. For the
uninitiated, HDF5 files can save arrays in arbitrary chunks, so that parts of
the (compressed) data can be accessed without reading in the whole array (see
XXXX).
As an example, here is the h5dump -H -p output for a MAT-file created by MATLAB
containing a 2000 x 1000 x 50 array (one “page” for each grayscale
image):
Note the array size ( 500, 1000, 2000 ) and the chunking CHUNKED ( 500, 125, 1 ).
The axes are reordered in the HDF file to be pages, columns, rows to
keep the data contiguous, so each chunk spans all pages, 125 columns, and a
single row. This means that to read a single page, we have to access all
the chunks. This is hard work for the ol’ laptop and shouldn’t have to be.
A newmatic Solution
Since MATLAB does not provide any control over chunk size, I wrote newmatic
to do just that.
There are two key functions in the package:
newmatic_variable is used to define the name, data type, array size, and
chunk size for variables created by newmatic
newmatic creates a MAT-file with the specified variables
Here is a small example demonstrating how to create a MAT-file with two arrays
(created by newmatic) and a cell array (not created by newmatic).
Use MATLAB to create the original file. This is a shortcut to getting all
the ancillary data MATLAB expects in the HDF5 file, so that MATLAB can read it
when we are done
Use the low-level HDF5 library tools packaged with MATLAB to create a new
file with the same formatting but with the user-specified chunking.
The h5dump -H -p output for an equivalent file created with my newmatic
tool (with chunks specified by me) is:
Now our chunks are a much happier CHUNKED ( 1, 1000, 2000 ). Each page is a
chunk, so the file is laid out to match the known access pattern.
This is nothing new, it is in fact the reason that HDF5 provides control over
chunking. Hopefully, Mathworks will take notice and one fine day give us
developers a bit more control over our data files.
]]>Intentionally Insulting Exceptions for Python2018-10-27T04:00:00+00:002018-10-27T04:00:00+00:00/jekyll/update/2018/10/27/insult-errorOne way I make myself laugh is by making my code print silly or insulting
messages when something goes wrong. Childish? Yes, but it helps brighten things
up when my code is inexplicably broken. This is all well and good, but I
thought I could do a bit better. What if:
The insulting messages were real Python Exceptions rather than lame print
statements, so that the program fails in a neat and tidy way.
The insults were random, so that I don’t get bored when the same problem
happens again and again.
The result of all this is a new package called insult_error. You can install
from PyPI or check out the code on
Github.
Automated Insults for Fun and Profit
The insult_error package provides a set of insulting exceptions you can use
to make your future self laugh, bother your collaborators, or both.
The core feature is the InsultError exception class, which behaves just like
a normal exception with a few differences:
The raised error is a randomly-selected subclass with a silly, insulting name
If no message is provided, the error will use a random insulting message
A special keyword argument rating provides some control over how offensive
you want the error and message to be
A few examples:
frominsult_errorimportInsultError# raise a random insult with a random message (defaults to "PG" rating)
raiseInsultError()# >>> NotThisAgain: Don't believe everything you think.
# raise a random insult with a user-specified message
raiseInsultError('This is my message')# >>> NotThisAgain: This is my message
# raise a random insult with <= PG rating
raiseInsultError(rating="PG")# >>> ForGodsSake: I don’t have the time or the crayons to explain this to you.
# raise a random insult with <= R rating
raiseInsultError(rating="R")# >>> FuckYouBuddy: I envy people who have never met you.
Implementation Details
There were two tricky bits in implementing this idea: first, how to throw a
random exception type, and second, how to enforce an internal “rating system”
to give users control over how risque they want to be.
To get random exceptions and messages when users raise an InsultError, I
(ab)used the __new__ method. This method gets called first when an object is
instantiated (before__init__ even), and returns an instance of the object.
I used this feature to make InsultError a class factory that returns a random
exception instance from the insult_error package. This is a wierd thing to do
– normally a factory method would be a @classmethod, but in this case I
wanted to mimic the usage of a normal Exception so a method call was out of
the question.
As an aside, the inspect module made it relatively easy to automatically
build lists of exception and message options from the package, without having
to write them out manually and maintain them.
To make ratings work, I added a rating attribute to all the exceptions and
methods, and grouped the list of options for exceptions and messages by these
ratings. This means that when the __new__ method is choosing one of each, I
can respect the users decision about what kind of insults are appropriate.
Help Me!
Most importantly, I would really welcome contributions to this package.
Random insults are much more fun if I didn’t write them all myself!
]]>Surface Slopes from LiDAR Data (or Fun With Zoning Regulations)2018-10-20T05:00:00+00:002018-10-20T05:00:00+00:00/jekyll/update/2018/10/20/somerville-slope
A friend of mine is working with the local zoning board on a rule regulating
“steeply” sloped lots in Somerville MA and asked me to do a quick analysis of
the number of impacted lots. This project turns out to build on some of the
datasets and skills I picked up while building my
Parasol Navigation app
during my time as an Insight Data Science Fellow.
The core challenge is a neat one: how can we compute the slope of the ground in
an urban environment? The key components to my solution were getting my hands
on high-resolution elevation observations of the ground surface (without
buildings), and figuring out a way to estimate local slopes on a specific
length scale from this noisy data.
If you want to run or extend this analysis, all of the code and data you need
are hosted at: github.com/keithfma/somerville-slope.
As always, feel free to contact me if you would like to discuss further.
Results: Lots of Steep Lots
The zoning rule of interest applies to “all natural slopes exceeding 25% over a
horizontal distance of 30 feet”. This sounds like pretty steep, but percent grade has
a weird definition: \(\frac{\Delta y}{\Delta x} * 100\). This means that a
100% grade is a slope of 1, or equivalently of 45 degrees, and that grade can
be more than 100%. The threshold slope for this rule is actually pretty modest:
7.5 feet of elevation change over a horizontal distance of 30 feet.
Given this definition, it is not surprising that there are many impacted lots
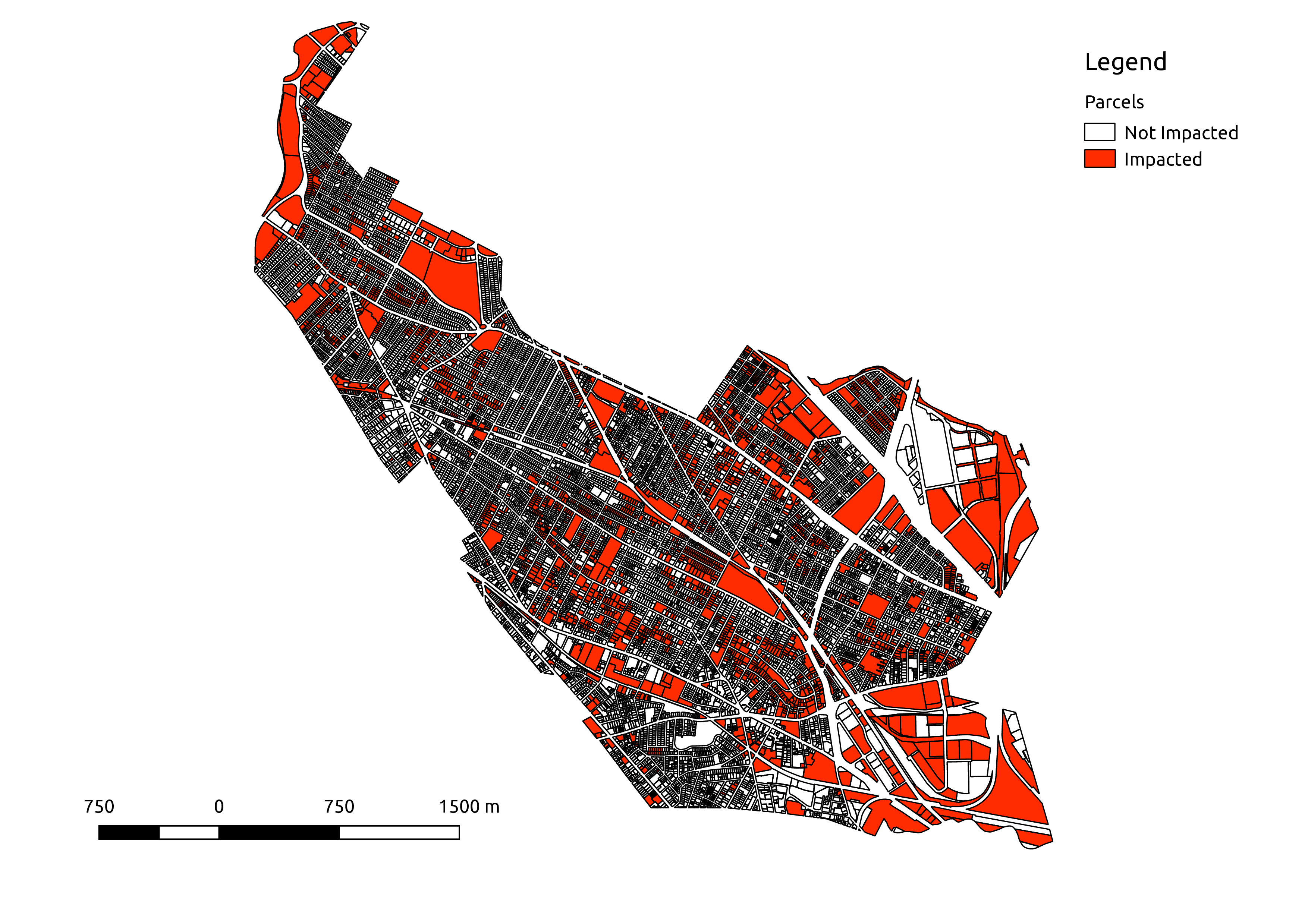
in hilly Somerville MA . I find that 2,370 of 13,354 tax parcels (~18%)
contain areas at > 25% grade. The impacted lots are found in clusters around
all of the hilly areas in the city.
This result should be of interest to the zoning board, as it was initially
assumed that the rule would impact only a few parcels. This is clearly not the
case – the rule would in fact come into play throughout the city.
Map of Somerville MA tax parcels with those impacted by the zoning rule highlighted in red.
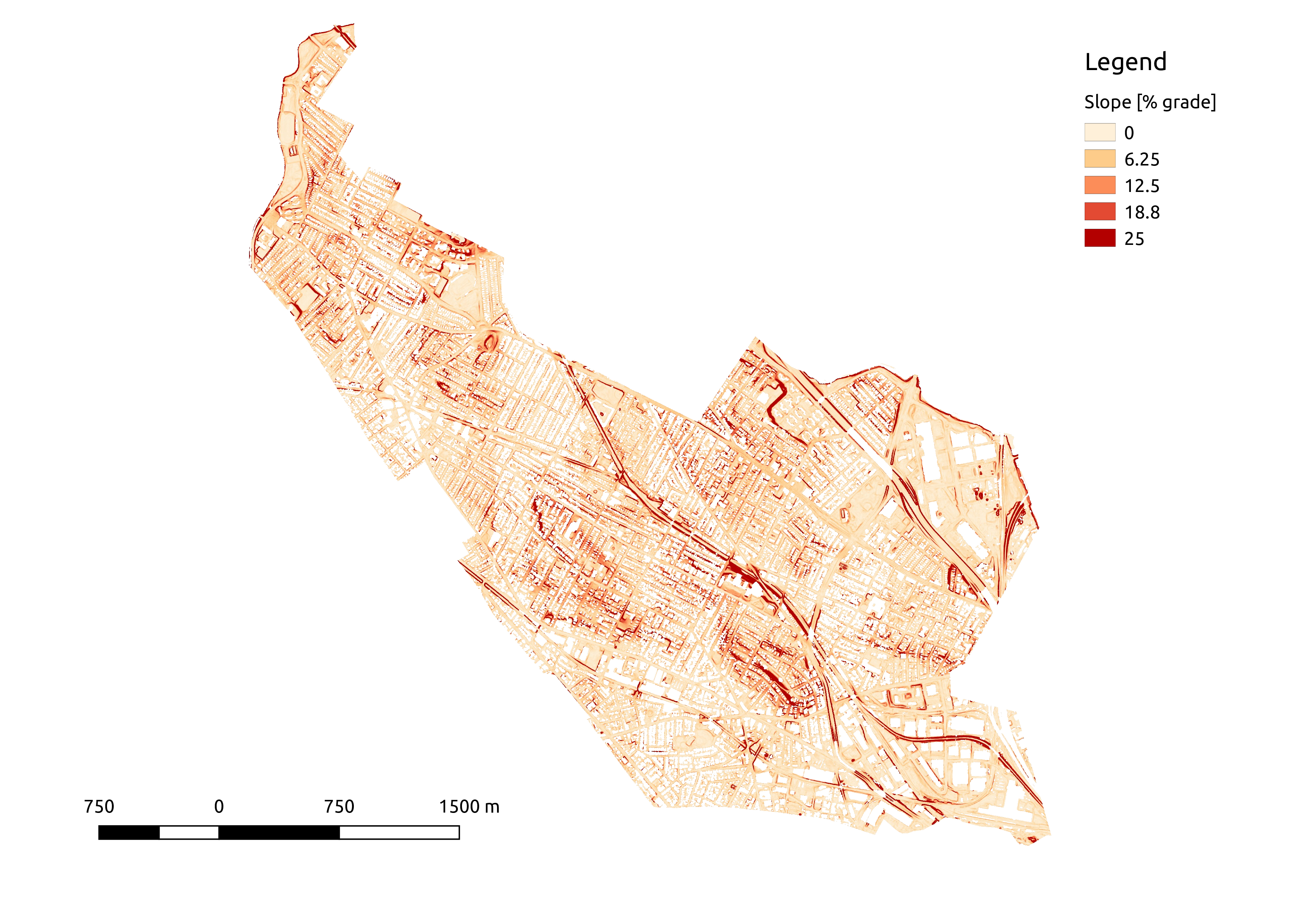
Surface slopes in Somerville MA as percent grade over a 30 foot length scale,
computed on a 1-meter grid from high-resolution lidar survey data. A few
notable features are 1) high slopes along major roadway and rail lines caused
by retaining walls at their margins, and 2) high slopes at the edges of parcels
on hilly terrain which are also caused by retaining walls at the edge of the
level lots buildings rest upon. Spot checking in Google Maps Street View show
that the high slopes at parcel edges are not due to buildings mislabeled as
ground observations, as I initially feared.
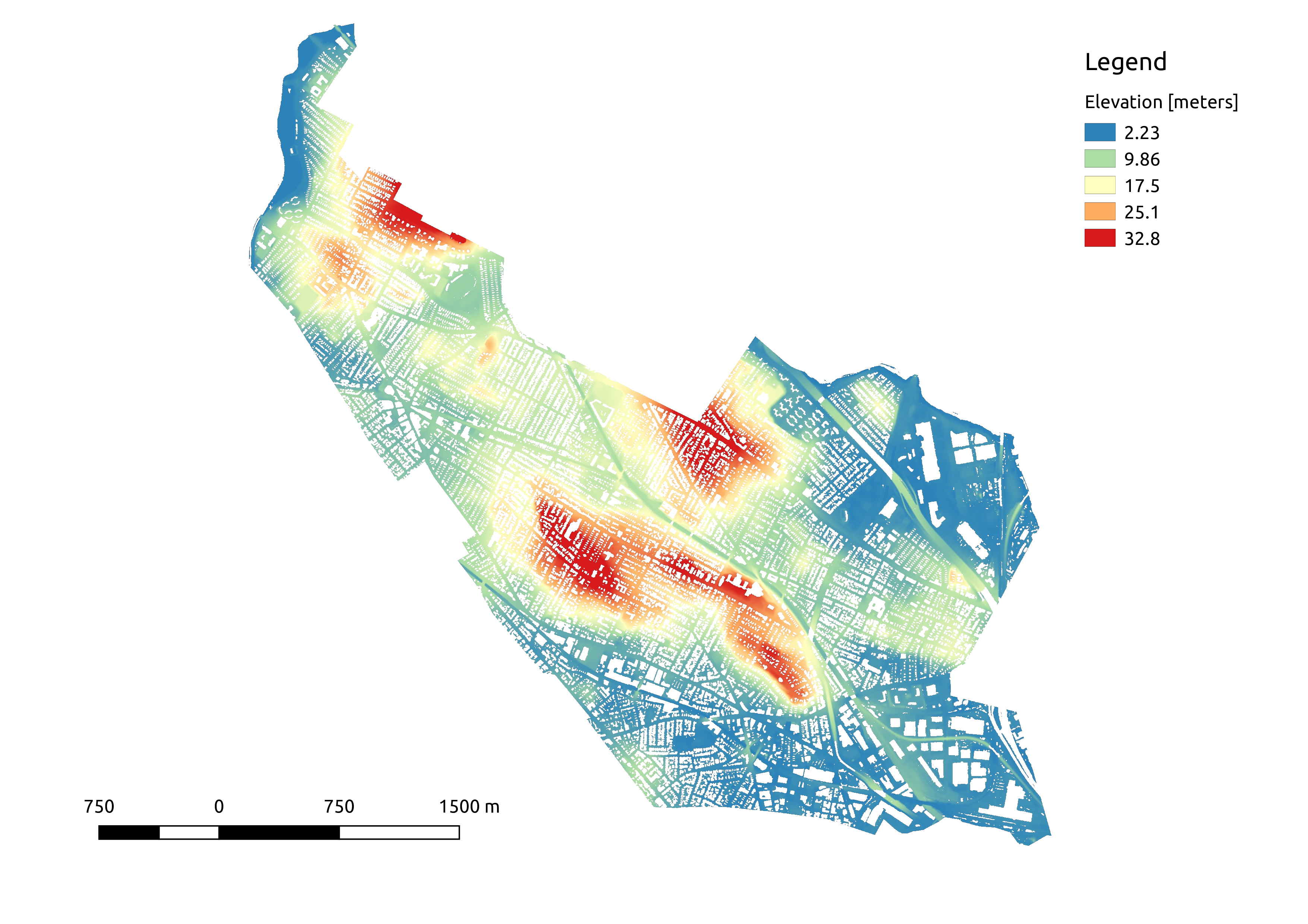
Surface elevations in Somerville MA, computed on a 1-meter grid from
high-resolution lidar survey data.
LiDAR Elevation from NOAA
Recent LiDAR surveys conducted in the aftermath of superstorm Sandy provide
coverage of the entire city of Somerville. Starting with a shapefiles of MA
towns from MassGIS and of the LiDAR tile footprints from NOAA, I gathered up 13
tiles from the NOAA server. Each tile has an average of 3.8 observations per
square meter. Nice!
One critical prerequisite for the ground slope analysis to work is that
estimated slopes must exclude buildings and trees. Happily, LiDAR contains some
extra information that helps in labeling and removing these above-ground
features (e.g. multiple returns from tree canopy and ground). Even more
happily, this LiDAR dataset classifies for all points as “default”, “ground”,
“water”, etc,, meaning that I can simply filter by the label to get the
ground-return-only dataset I need.
In total, this ground-only dataset contains ~36 million elevation observations.
There are “holes” wherever buildings were removed from the dataset, but we do
have observations from the ground below the tree canopy.
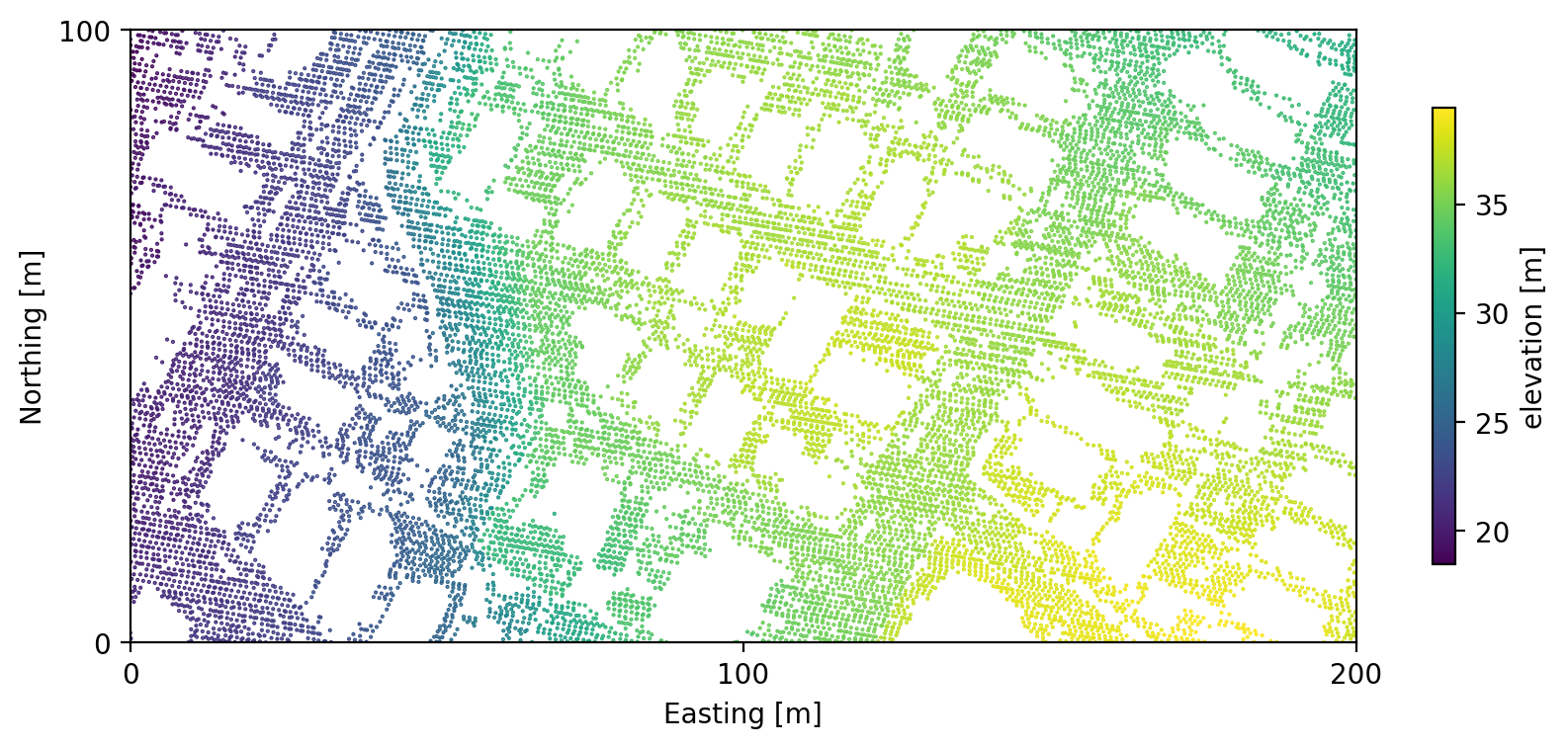
Example of the ground-only lidar observations used for the slope calculation.
This figure shows just a small (200 x 100 meter) region along the edge of a
hill. Gaps in the data are a good thing here - observations of the built
environment have been filtered out convincingly by the data providers.
Analysis: 25,781,323 Least Squares Fits
With the elevation data in hand, the next step is to compute local slopes
throughout the city. The trick here is that the zoning regulation applies to
slopes over a 30-foot length scale. This means that the usual approach of
gridding the elevations and using finite differences to approximate the local
gradient is a no-go – this would not give the correct lengthscale.
Instead, I decided to estimate the “30-foot slopes” for each point using the
best-fit plane to the points within a 15-foot radius. This approach has the
advantage that it includes all of the elevation information in the specified
area around a point, and simultaneously estimates elevation and slope
magnitude and direction.
To dig in just a little, each planar fit finds a plane defined as \(z = ax + by
+c\), with the free parameters \(a, b, c\) determined by a standard least
squares minimization. Given this equation, the estimate for elevation at a
point \((x^\prime, y^\prime)\) is simply \(z^\prime = a x^\prime + b y^\prime +c\).
The local slope has components \(\frac{\partial z}{\partial x} = a\) and
\(\frac{\partial z}{\partial y} = b\), with magnitude \(\sqrt{a^2 + b^2}\) and
direction \(\arctan \left( \frac{b}{a} \right)\).
The calculation is fairly laborious. I created a regular grid with 1 meter
spacing over the whole city and a binary mask indicating which points are
inside the city limits. Then for each point in this grid, I extracted the LiDAR
observations within 15 feet. To make this extraction feasible, I used a KDTree
to speed up the spatial lookup (cKDTree
is your friend!). Then I solved for the best-fit plane using least squares
using numpy.linalg.lstsq
to handle all the possible numerical pitfalls for me.
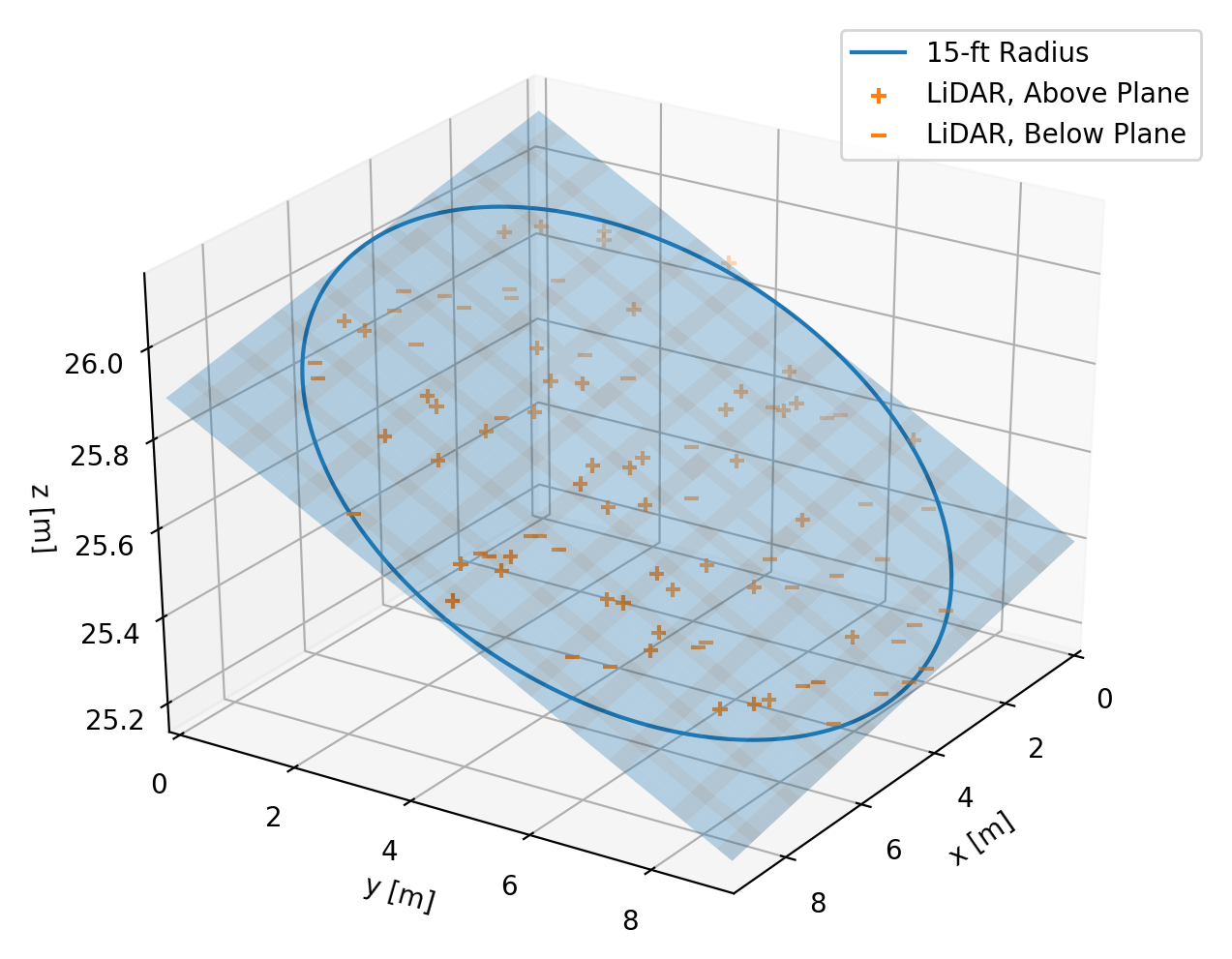
LiDAR observations and best-fit plane for points within 15-foot neighborhood.
One of the many, many least squares fits that I used to estimate gridded
elevation and slope.
One thing I was worried about in this analysis was the possibility of errors in
the original data classification. If there were any points labeled as “ground”
that were in fact the edge of some tall building, then I might end up computing
erroneously high slopes at the edge of buildings. This would be a serious flaw,
given that this is an urban environment and high slopes are the key result I
was looking for. To mitigate this risk, I only computed slopes around points
whose local 30-foot neighborhood was well populated – with at least 75% of the
number of observations expected for an area with no data gaps. This decision
eroded slightly the area where I could compute slopes, but in return increased
my confidence in the results. This potential issue is not readily apparent in
the results, which suggests the procedure worked as expected.
From Slope to Impacted Parcels
The last step was to count the parcels in the city that would be impacted by
the zoning regulation. Using a shapefile of the Somerville tax parcels provided
by MassGIS, I summed the area with above-threshold (>25%) slope in each parcel.
To be conservative in my count, I set an (arbitrary) cutoff of 5 m2
above-threshold slope. Parcels with more than 5 m2 of above-threshold slope
were labeled as “impacted”, and all others were labeled as “not impacted”.
]]>Parasol Navigation: Optimizing Walking Routes to Keep You in the Sun or Shade2018-08-07T14:20:24+00:002018-08-07T14:20:24+00:00/jekyll/update/2018/08/07/introducing-parasol
Sun and shade have a strong impact on how many of us pick a route to the places
we want to go. For me personally, direct sun is the devil himself. The point of
Parasol is to leverage knowledge of the environment to help people make these
decisions. This is analogous to how we use popular navigation apps like Google
Maps or Waze to navigate around traffic: we want to avoid congested routes and
the apps use extra information about current conditions to help us do so. The
Parasol navigation app knows more about where it is sunny and shady than you
do, and can help you stick to whichever is your favorite.
I built Parasol over 4 weeks as an independent project with Insight Data Science.
I cannot recommend this fellowship highly enough. If you are a PhD considering
a career in data science, apply to Insight.
If you are a company looking for newly minted data scientists, become a partner.
Parasol uses high-resolution elevation data to simulate sunshine and constructs
routes that keep users in the sun or shade, whichever they prefer. You can
try out the app at parasol.allnans.com.
The app is no longer live, but you can still check out the demo video below:
The demo starts by finding the shortest-distance path between the Esplanade and
South Station in Boston. Next, I turn on the sun/shade layer, with light colors
indicating sun and dark colors indicating shade. Then, I use the sun/shade
preference slider to update the route to prefer shade, and show that the
resulting route is 19% longer than the shortest path and has 13% less sun.
Shifting the slider to prefer sun yields a different route that is 5% longer
than the shortest path with 18% more sun. Finally, I change the time-of-day and
show a new best-sunny-route that is 2% longer and has 25% more sun.
Approach
The approach behind Parasol is surprisingly straightforward. First, I build a
high-resolution elevation model. Next, I simulate sun/shade using the position
of the sun for a given date and time to illuminate the elevation grid. Then, I
compute a cost function that incorporates sun/shade as well as distance
for each segment of the transportation network. Finally, I apply Dijkstra’s
algorithm to compute the shortest path given this custom cost. All of this is
wrapped up into a friendly web application.
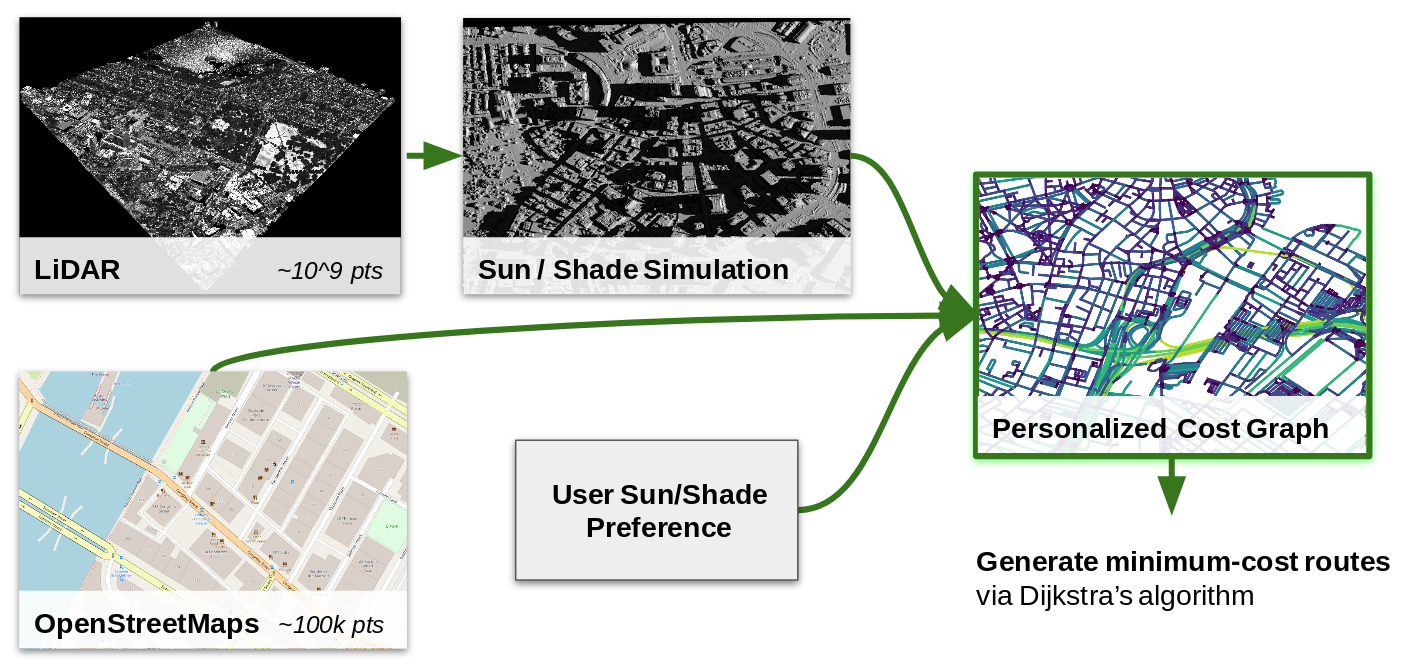
To make this a little easier to follow, the figure below shows a high-level
schematic of the inputs and outputs of the system. Later sections provide some
insight into how I designed and implemented each part of the system.
Parasol system overview, showing the input data used to build minimum cost routes that incorporate distance and user sun/shade preference.
To run a decent shade model, I needed a decent elevation model. My goal was to
build two elevation grids: one for the “upper surface” including buildings,
trees, etc., and one for a “lower surface” that excludes these things. For my
purposes, the sun shines on the upper surface, and the people walk on the
lower.
LiDAR (Light Detection and Ranging) scan data is a near perfect data source
for my application. The raw data consists of a “point cloud”, meaning a long
list of (x, y, z, …) points, with a <1 meter spacing. Even better,
each laser shot can have multiple returns, so that it is possible to
resolve both tree top canopy and bare ground elevation.
The first challenge was separating the point cloud into upper and lower subsets
(i.e., tree-tops and bare ground). The are a few well-established methods for
doing so, but it turns out the LiDAR data I used were pre-classified by NOAA.
As these classifications were quite good, I just used them straight out of the
box.
Now I had two point clouds, but still no grids. LiDAR data are not on a
nice regular grid, but rather scattered about with irregular spacing. Because
there is some noise in the measured elevation, I needed to smooth (not
interpolate) the raw data and then resample on a regular grid. This
is trickier than one might expect, especially because features with sharp edges
(e.g. buildings) are important to the sun/shade simulation. I used a
nearest-neighbor median filter, which returns the median value of the
k-nearest neighbors for each point on the output grid. This has the nice
effect of both smoothing the noise in the data and preserving sharp edges.
Median filters are common for image de-noising, but I had to implement my own to
work with scattered input data. For the interested, you can
find the code for my nearest-neighbor median filter here
— it is quite simple!
Example of the input LiDAR point cloud, and the computed upper and lower surface grids (1 meter resolution).
Simulating Sunshine
To simulate sun and shade, I use the GRASS GIS module r.sun to compute
insolation on the upper surface grid for a given date and time. This simulation
includes raycasting for direct sun, as well a diffuse illumination from
scattered light. It is not fast, nor is it easy to use, but it gets the job
done.
Simulated insolation near the Prudential Center, Boston for each hour from 5 AM
- 7 PM on July 20th, 2018. Light colors indicate higher insolation. Pretty, no?
I also did a quick qualitative validation in which I compared simulated shadows
to the observed shadows in high-resolution aerial photography (from the NAIP
program).
Comparison of observed shadows in NAIP aerial imagery and simulated shadows
created by Parasol. Comparisons like this served as a qualitative "smell test"
to make sure the solar simulation worked acceptably well.
To account for shade cast by trees, I set the insolation at all pixels where
the upper surface is higher than the lower surface (i.e., where the user will
be walking below some object) and set it to the minimum observed insolation in
the scene. A more sophisticated approach might account for sunlight angling in
under the trees, or for the changing leaf cover in each season, but these
features were sadly out of scope for this quick project.
Sun and Shade Cost
Dijkstra’s algorithm (which I used) finds minimum cost routes between nodes on
a weighted graph. The weights are essentially a cost incurred for traversing
between two nodes. An obvious choice for the cost in a navigation application
is the distance between the nodes. For Parasol, I needed a new cost function
that included sun/shade exposure in addition to distance. The key requirements
for the cost function were:
Incorporate both insolation and distance
Allow for routes that prefer sun and well as routes that prefer shade
Have a minimal number of free parameters (ideally one) so that it is easy
for users to indicate their preference
Be non-negative
It turns out I was able to write the cost as a simple weighted average of a
“sun cost” and a “shade cost”:
The weighting parameter (\(\beta\)) reflects a user’s preference for sun or
shade. It ranges from 0 (total preference for shade) to 1 (total preference for
sun).
The “sun cost” term is the path integral of the insolation along each segment
of the OpenStreetMaps transportation network. This is related to the amount of
sun you would absorb by walking a given segment. The beautiful thing about
integrating over the length of each segment is that the cost implicitly
includes the length of the segment – it is the average insolation times the
segment length.
It turns out there is a problem with this super simple approach: insolation is
on the order of 1000 \(W/m^2\), whereas route lengths are on the order of 10
\(m\), which means sun is much more important than distance in the total cost.
From experience, I can say that this leads to some very crazy routes. To fix
this problem, I rescale the insolation to the range 0 to 1 prior to computing
the cost. This amounts to giving distance and insolation equal weights in the
cost function. In practice, this generates sane routes so I stopped here, but
it would be very interesting to explore what scaling would lead to an “optimal”
cost function. Letting \(I\) be the normalized insolation, the sun cost is:
\[\text{sun_cost} = \int_s I \,ds\]
Moving on, the “shade cost” term is a bit weirder than the “sun cost”, it is
the path integral of the reduction in insolation due to shade along each
segment in the transportation network. This is related to the amount of sun
avoided by the shade cast on each segment. I compute the shade cost as the
difference between the maximum insolation and the observed insolation. Since
the insolation is normalized (has a maximum value of 1), this amounts to:
\[\text{shade_cost} = \int_s 1 - I \,ds\]
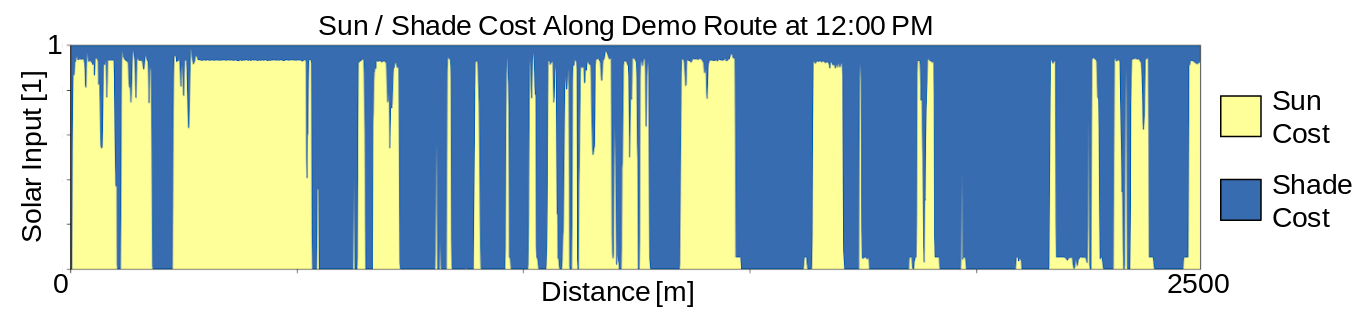
Example of the sun and shade cost components for the route shown in the demo
video above (i.e., from the Boston Esplanade to South Station).
Here is the fun part: if the user sets \(\beta = 0.5\), then we recover the
shortest-length path! Working this through shows that the cost in this case is
just the path integral of a constant, which is proportional to the length.
Voila! A single-parameter cost function that allows users to choose sunny or
shady routes and still cares about distance.
Routing with a Sun/Shade Cost
The heavy lifting for computing the route is handled by the wonderful
PostgreSQL extension, pgRouting. This extension computes least-cost routes
using a variety of algorithms (I used Dijkstra) and allows the user to specify
the cost as a function of the columns in an OpenStreetMap database. All I had
to do was to write the computed sun and shade cost for each segment of the
transport network to my database, choose the right column to use based on the
time of day, and apply my simple cost equation.
Web App
I won’t go into the details, but I set up the web app using Python and Flask to
host an API with endpoints for generating routes, etc., used Leaflet with a few
wonderful extensions to build an interactive map, and hosted the sun/shade
simulation images using Geoserver.
Next Steps
My biggest hope for Parasol is that the idea catches some traction and gets
picked up and integrated into one (or more!) of the many wonderful navigation
apps out there in the wild. A few things I had hoped to tackle but ran out of
time for are:
Use sidewalks rather than roads for routing. While OpenStreetMaps includes special tags for
sidewalks, coverage is woefully incomplete. This is
problematic because Parasol is not able to advise user’s to take advantage of
streets where one sidewalk is shady. A few ways to go about this might be (1)
trying to synthesize a sidewalk graph, or (2) adjust the sun and shade costs to
follow the best side of each street.
Adjust shade to account for seasonal tree cover. It is definitely possible
to identify trees from the LiDAR data, and the shade cast by these trees could
be adjusted based on the season. Even better, it is probably possible to use
satellite imagery to drive the timing of the change.
Better raycasting! I used GRASS GIS, which worked fine, but it would likely
be better to take advantage of the wonderful machinery that drives modern
computer graphics instead. An additional benefit would be that the LiDAR could
be converted to a proper 3D model, rather than an elevation grid, and the ray
casting could handle the edges of obstructing objects better.
]]>MV Polar Bears Attendence Data Exploration and Forecasting2018-07-19T14:20:24+00:002018-07-19T14:20:24+00:00/jekyll/update/2018/07/19/mv-polar-bearsFor the past several years, the wonderful MV Polar Bears group has recorded how
many people attend each day. This post provides some basic visualizations of
the dataset and an attempt to build a predicitive model to forecast the
expected number of attendees. My big takeaways were:
The MV Polar Bears are reaching an amazing number of people - wow!
The bears are very unpredictable.
Attendence Over Time
The next plot shows the number of new and returning attendees over the
past few years. There is a clear annual pattern, and always more old
friends than new ones.
Polar bears are slowly creeping towards work domination! The plot below
shows the cumulative number of attendees (blue) and new polar bear
members (green) over time. The numbers are big and growing.
What Drives Attendence?
Two features are related if knowing the value of one feature tells you
something about the other. For example, the new and returning attendence
number are closely correlated – when the group is bigger there are more
“newbies”. Temperature and attendence show a different relation. Polar
bears don’t sweat cold weather up to a point, and then attendence falls
off a cliff. Take a look and see what else you can find.
Forecast Model
Polar bears are hard to predict! You may notice from the plots above that
attendence varies wildly from day-to-day, and the magnitude of this
variation changes over time as well. These features make make building a
predictor tricky. Moreover, I had hoped that the weather and water
conditions might help to predict attendence, but it seems that Polar
Bears aren’y much bothered by cold, wind, or rain.
After a bit of experimentation, I landed on a timeseries forecasting
model that predicts changes in the mean and volitility (specifically a
GARCH model with an ARX mean). The plot below shows retrospecitve
predictions for the attendence dataset (top), as well as the prediction
errors (bottom).
You may notice that the prediction is often really wrong. Like I
said, it is hard to predict polar bears! The volitility prediction works
better – the true number is usually within the (1-sigma) margin of
error.
]]>Beautiful Streamlines for Visualizing 2D Vector Fields2018-04-04T14:20:24+00:002018-04-04T14:20:24+00:00/jekyll/update/2018/04/04/beautiful-streamlinesAs part of my PhD research, I measured velocity fields from a laboratory-scale
model of a mountain belt in mid-collision. This post discusses some work I did
to visualize the results, which I hope others my find useful – vector fields
being ridiculously common in many disciplines. To cut to the chase, you can
find a MATLAB implementation of the Jobard & Lefer streamline plotting algorithm
at the links below, which you can use to generate plots like you see in the
figure below.
Incidently, a few months after I wrote this package, I learned that my good
friend Chris Thissen had been doing the same thing at
the same time. It turns out that we both got the reference from our PhD
advisor, decided it was useful enough to share with the world, and quietly set
to work coding it up. You can find Chris’s (also excellent) implementation at
the following link: estream2.
About streamlines
Streamlines are a clean and informative way to visualize the direction of a
velocity field. Simply put, a streamline is a line everywhere tangent to a
vector field. I will leave it at that, but not that Wikipedia provides a nice
discussion (and visualization) of what streamlines are and are not
(Wikipedia - Streamlines).
To draw a streamline, you pick a starting point, evaluate the vector field at
that point, step forward an increment in that direction, and repeat many, many
times. In other words, you numerically integrate the path from your starting
point. This is typically done with a straightforward, reliable method like
Runga-Kutta.
While this is not so hard to implement yourself, most scientific computing
languages have tools to do the dirty work for you. For example, in MATLAB, you
might use a built-in ODE solver to handle the
numerical integration then plot the line manually, or call the
streamline function to compute and plot the
line.
One big problem remains: where should you place the start-points for your
streamlines? This does not matter much for quick-and-dirty data analysis, but
it should when making plots for publication. Edward Tufte, a guru of scientific
visualization, said that the goal of our figures should be to achieve an
“economy of understanding” for the reader. He is right, and so it is up to us
to put in the work to make our figures as expressive as possible. For
streamlines, this means picking start-points such that the streamlines span
the data with a consistent density – which is harder than it sounds.
Bruno Jobard and Wilfred Lefer’s 1997 paper,
Creating Evenly-Spaced Streamlines of Arbitrary Density,
provides a neat algorithm to solve the spacing problem, and a few additional
formatting tricks that make beautiful and informative streamline plots. A few
years back, I implemented their algorithms in MATLAB, and posted the package to
Github and the Mathworks FileExchange (see links at top). Below, I will briefly
discuss the various plots it can make, and how it makes them.
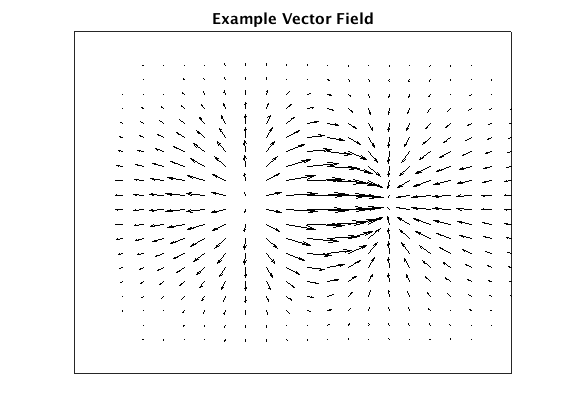
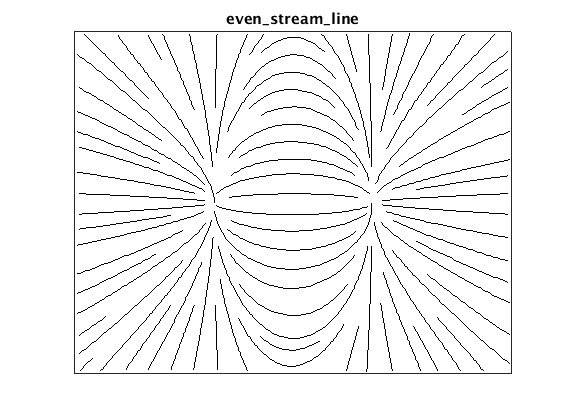
Evenly-spaced streamline plot
First the result. Using the velocity field below as an example:
Plotting streamlines using Jobard and Lefer’s algorithms to select start and
end points for each line, we get the following plot:
One particularly nice feature of the algorithm is that we can explicitly (and
independently) set the maximum and minimum streamline spacing. This provides a
lot of space for customization with minimal parameters to fiddle with.
A bit about the algorithm itself. The basic idea is simply to draw streamlines
until they are too close to their neighbors, then stop. Practically, this means
selecting a start point, integrating forward from that point, and checking
distance to all existing streamline points at each step. New start points are
selected by generating candidates at some distance from the existing
streamlines, and accepting those that are sufficiently far from their
neighbors. This process of generating a start point and adding a new
streamline, continues until no more lines can be added at the specified minimum
spacing.
Two parameters control the spacing, dsep, the minimum distance from all
streamlines to the start point of a new line, and dtest the minimum distance
between any streamline. The authors recommend dtest = 0.5*dsep, which means
the streamline density varies over the plot – higher in regions where the
streamlines converge and lower where they diverge.
All this distance-checking sounds computationally expensive! To make it
feasible, the authors use a low-res grid and keep track of which “cells”
contain streamlines already. Checking for neighboring streamlines then only
requires checking the neighboring grid cells, instead of computing distances to
all points.
It is worth noting that MATLAB’s streamslice
now includes similar functionality through a single density parameter. It
does not, however, provide control over both minimum and maximum density, nor
the fancy plot variants below.
Streamline plot with arrow glyphs
Since simple streamlines do not indicate direction, it is useful to add arrows
along their length. This can be done easily by placing glyphs at some specified
distance interval along each line.
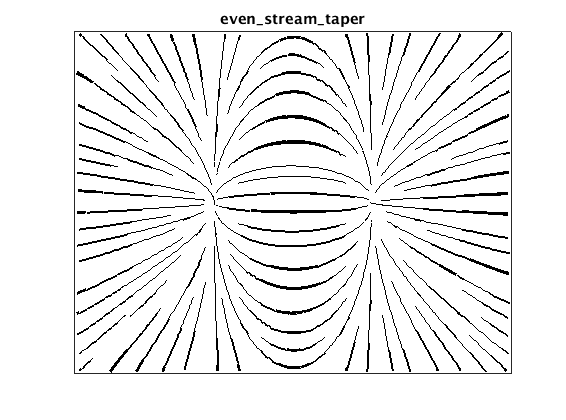
Tapered streamline plot
We can use the distance between lines to generate tapered lines, what Jobard &
Lefer refer to as a “hand-drawn” style. To do this, we scale the width of the
line based on distance to the nearest neighbor, up to some maximum width.
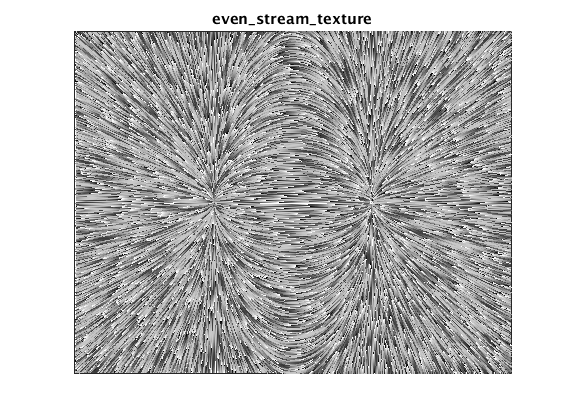
Textured streamline plot
The last option is to generate a textured plot by shading each streamline in a
sawtooth-like pattern. When these shaded lines are plotted densely, the provide
a quite detailed view of the vector field while still indicating flow
direction. The effect is similar to the line-integral-convolution (LIC) method,
but (I think) simpler to understand and implement.
References
Jobard, B., & Lefer, W. (1997). Creating Evenly-Spaced Streamlines of Arbitrary
Density. In W. Lefer & M. Grave (Eds.), Visualization in Scientific Computing
’97: Proceedings of the Eurographics Workshop in Boulogne-sur-Mer France, April
28–30, 1997 (pp. 43–55). inbook, Vienna: Springer Vienna.
http://doi.org/10.1007/978-3-7091-6876-9]